Tags
In my last job, I was a frequent flyer. Each week I flew between 2 or 3 countries, briefly returning for 24 hours on the weekend to get a change of clothes. My favourite airlines were Cathay Pacific, Emirates and Singapore Air. Now, unless you have been living in a cave, you’d be well aware of the recent news story of how United Airlines removed David Dao from an aircraft. I wondered how that incident had affected United’s brand value, and being a data scientist I decided to do sentiment analysis of United versus my favourite airlines.
Way back on 4th July 2015, almost two years ago, I wrote a blog entitled Tutorial: Using R and Twitter to Analyse Consumer Sentiment. Even though that blog post is one of my earliest, it continues to be the most popular, attracting just as many readers per day as when I first wrote it.
Since the sentiment package, upon which that blog was based, is no longer supported by CRAN, and many readers have problems with the manual and technical process of installing an obsolete package from an archive, I have written a new blog using a different, live CRAN package. The syuzhet package was published only several weeks ago, and offers a range of different sentiment analysis models. So I’ve started to try it out.
I have collected tweets for 4 airlines:
- Cathay Pacific
- Emirates
- Singapore Air
- United Airlines
The tweet data starts at 01-Jan-2015 and go up to mid-April 2017.
Step 1: Load the tweets and load the relevant packages
library(foreign)
library(syuzhet)
library(lubridate)
library(plyr)
library(ggplot2)
library(tm)
library(wordcloud)
# get the data for the tweets
dataURL = 'https://s3-ap-southeast-1.amazonaws.com/colinpriest/tweets.zip'
if (! file.exists('tweets.zip')) download.file(dataURL, 'tweets.zip')
if (! file.exists('tweets.dbf')) unzip('tweets.zip')
tweets = read.dbf('tweets.dbf', as.is = TRUE)
I’ve stored the tweets in a dbf file and zipped it. The zip file is 68MB in size, and the dbf file is 353MB. The code shown above downloads the zip file, extracts the dbf and then reads the dbf file into a data.frame.
Step 2: Do Sentiment Scoring using the syuzhet package
# function to get various sentiment scores, using the syuzhet package
scoreSentiment = function(tab)
{
tab$syuzhet = get_sentiment(tab$Text, method="syuzhet")
tab$bing = get_sentiment(tab$Text, method="bing")
tab$afinn = get_sentiment(tab$Text, method="afinn")
tab$nrc = get_sentiment(tab$Text, method="nrc")
emotions = get_nrc_sentiment(tab$Text)
n = names(emotions)
for (nn in n) tab[, nn] = emotions[nn]
return(tab)
}
# get the sentiment scores for the tweets
tweets = scoreSentiment(tweets)
tweets = tweets[tweets$TimeStamp < as.Date('19-04-2017', format = '%d-%m-%Y'),]
The syuzhet package offers a few different algorithms, each taking a different approach to sentiment scoring. It also does emotion scoring based upon the nrc algorithm. The code above calculates scores using the syuzhet, bing, afinn and nrc algorithms, adding columns with the scores from each algorithm.
Step 3: Visualise the Sentiment Scores
# function to find the week in which a date occurs
round_weeks <- function(x)
{
require(data.table)
dt = data.table(i = 1:length(x), day = x, weekday = weekdays(x))
offset = data.table(weekday = c('Sunday', 'Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday', 'Saturday'),
offset = -(0:6))
dt = merge(dt, offset, by="weekday")
dt[ , day_adj := day + offset]
setkey(dt, i)
return(dt[ , day_adj])
}
# get daily summaries of the results
daily = ddply(tweets, ~ Airline + TimeStamp, summarize, num_tweets = length(positive), ave_sentiment = mean(bing),
ave_negative = mean(negative), ave_positive = mean(positive), ave_anger = mean(anger))
# plot the daily sentiment
ggplot(daily, aes(x=TimeStamp, y=ave_sentiment, colour=Airline)) + geom_line() +
ggtitle("Airline Sentiment") + xlab("Date") + ylab("Sentiment") + scale_x_date(date_labels = '%d-%b-%y')
# get weekly summaries of the results
weekly = ddply(tweets, ~ Airline + week, summarize, num_tweets = length(positive), ave_sentiment = mean(bing),
ave_negative = mean(negative), ave_positive = mean(positive), ave_anger = mean(anger))
# plot the weekly sentiment
ggplot(weekly, aes(x=week, y=ave_sentiment, colour=Airline)) + geom_line() +
ggtitle("Airline Sentiment") + xlab("Date") + ylab("Sentiment") + scale_x_date(date_labels = '%d-%b-%y')
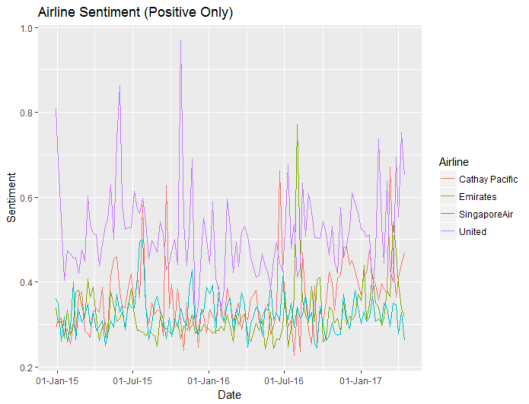
The code above summarises the sentiment for each airline across time. The first plot shows the daily sentiment values for each airline:
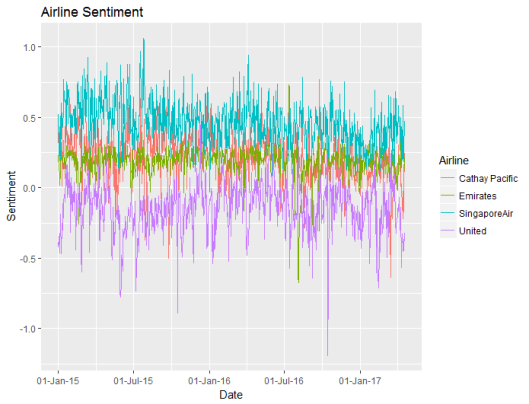
Based upon the bing sentiment algorithm, United has the poorest sentiment, and Singapore has the best sentiment. United usually has negative sentiment. Daily to day random fluctuations in sentiment make this a cluttered graph, so I decided to summarise the sentiment weekly instead of daily:
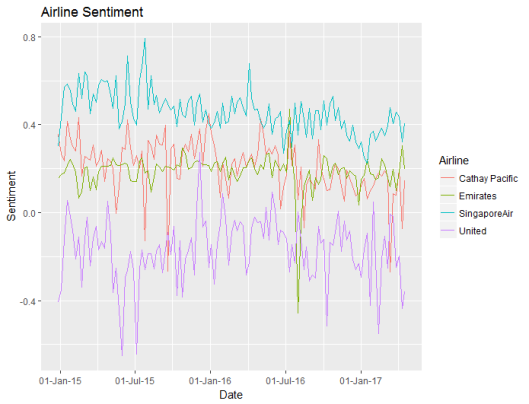
Now it’s easier to see the differences in sentiment between the four airlines. While Emirates and Cathay Pacific have similar levels of sentiment, the values for Emirates are more stable. This, however, may be due to the sheer volume of tweets about Emirates versus the smaller number of tweets about Cathay Pacific.
Step 4: Compare the Sentiment Algorithms
The sentiment scores above use the bing algorithm, but we should check whether the different algorithms produce different results.
# compare the sentiment for across the algorithms
algorithms = tweets[rep(1, nrow(tweets) * 4), c("week", "syuzhet", "Airline", "Airline")]
names(algorithms) = c("TimeStamp", "Sentiment", "Algorithm", "Airline")
algorithms$Algorithm = "syuzhet"
algorithms[seq_len(nrow(tweets)), c("TimeStamp", "Sentiment", "Airline")] = tweets[,c("TimeStamp", "syuzhet", "Airline")]
algorithms[nrow(tweets) + seq_len(nrow(tweets)), c("TimeStamp", "Sentiment", "Airline")] = tweets[,c("TimeStamp", "bing", "Airline")]
algorithms$Algorithm[nrow(tweets) + seq_len(nrow(tweets))] = "bing"
algorithms[2 * nrow(tweets) + seq_len(nrow(tweets)), c("TimeStamp", "Sentiment", "Airline")] = tweets[,c("TimeStamp", "afinn", "Airline")]
algorithms$Algorithm[2 * nrow(tweets) + seq_len(nrow(tweets))] = "afinn"
algorithms[3 * nrow(tweets) + seq_len(nrow(tweets)), c("TimeStamp", "Sentiment", "Airline")] = tweets[,c("TimeStamp", "nrc", "Airline")]
algorithms$Algorithm[3 * nrow(tweets) + seq_len(nrow(tweets))] = "nrc"
# get the algorithm averages for each airline
averages = ddply(algorithms, ~ Airline + Algorithm, summarize, ave_sentiment = mean(Sentiment))
averages$ranking = 1
for (alg in c("syuzhet", "bing", "afinn", "nrc")) averages$ranking[averages$Algorithm == alg] = 5 - rank(averages$ave_sentiment[averages$Algorithm == alg])
averages = averages[order(averages$Airline, averages$Algorithm), ]
The code above was a bit clumsy – I probably should have used reshape.
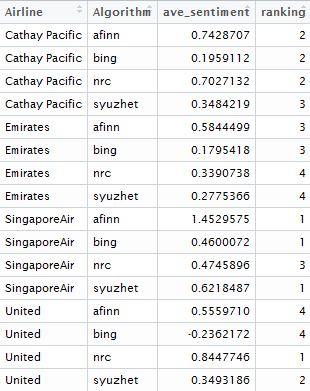
The different algorithms give similar rankings between the airlines with one big exception: the nrc algorithm is surprisingly positive about United and unusually negative about Singapore Air compared to the other algorithms. This goes to show that sentiment analysis isn’t just a plug and play technique and also means that a warning should be applied to the emotion analysis shown in Step 5 below, as it is based upon the nrc algorithm!
Step 5: Emotion Analysis
Noting the warning, from the previous section, let’s compare the emotions between the airlines and between tweets, using the nrc algorithm.
ggplot(weekly, aes(x=week, y=ave_negative, colour=Airline)) + geom_line() +
ggtitle("Airline Sentiment (Positive Only)") + xlab("Date") + ylab("Sentiment") + scale_x_date(date_labels = '%d-%b-%y')
ggplot(weekly, aes(x=week, y=ave_positive, colour=Airline)) + geom_line() +
ggtitle("Airline Sentiment (Negative Only)") + xlab("Date") + ylab("Sentiment") + scale_x_date(date_labels = '%d-%b-%y')
ggplot(weekly, aes(x=week, y=ave_anger, colour=Airline)) + geom_line() +
ggtitle("Airline Sentiment (Anger Only)") + xlab("Date") + ylab("Sentiment") + scale_x_date(date_labels = '%d-%b-%y')
# function to make the text suitable for analysis
clean.text = function(x)
{
# tolower
x = tolower(x)
# remove rt
x = gsub("rt", "", x)
# remove at
x = gsub("@\\w+", "", x)
# remove punctuation
x = gsub("[[:punct:]]", "", x)
# remove numbers
x = gsub("[[:digit:]]", "", x)
# remove links http
x = gsub("http\\w+", "", x)
# remove tabs
x = gsub("[ |\t]{2,}", "", x)
# remove blank spaces at the beginning
x = gsub("^ ", "", x)
# remove blank spaces at the end
x = gsub(" $", "", x)
return(x)
}
# emotion analysis: anger, anticipation, disgust, fear, joy, sadness, surprise, trust
# put everything in a single vector
all = c(
paste(tweets$Text[tweets$anger > 0], collapse=" "),
paste(tweets$Text[tweets$anticipation > 0], collapse=" "),
paste(tweets$Text[tweets$disgust > 0], collapse=" "),
paste(tweets$Text[tweets$fear > 0], collapse=" "),
paste(tweets$Text[tweets$joy > 0], collapse=" "),
paste(tweets$Text[tweets$sadness > 0], collapse=" "),
paste(tweets$Text[tweets$surprise > 0], collapse=" "),
paste(tweets$Text[tweets$trust > 0], collapse=" ")
)
# clean the text
all = clean.text(all)
# remove stop-words
# adding extra domain specific stop words
all = removeWords(all, c(stopwords("english"), 'singapore', 'singaporeair',
'emirates', 'united', 'airlines', 'unitedairlines',
'cathay', 'pacific', 'cathaypacific', 'airline',
'airlinesunited', 'emiratesemirates', 'pacifics'))
#
# create corpus
corpus = Corpus(VectorSource(all))
#
# create term-document matrix
tdm = TermDocumentMatrix(corpus)
#
# convert as matrix
tdm = as.matrix(tdm)
#
# add column names
colnames(tdm) = c('anger', 'anticipation', 'disgust', 'fear', 'joy', 'sadness', 'surprise', 'trust')
#
# Plot comparison wordcloud
layout(matrix(c(1, 2), nrow=2), heights=c(1, 4))
par(mar=rep(0, 4))
plot.new()
text(x=0.5, y=0.5, 'Emotion Comparison Word Cloud')
comparison.cloud(tdm, random.order=FALSE,
colors = c("#00B2FF", "red", "#FF0099", "#6600CC", "green", "orange", "blue", "brown"),
title.size=1.5, max.words=250)
The code above plots the emotions across time for each airline.



United Airlines attracts more angry tweets, and this has spiked in April 2017 following the David Dao incident. But United Airlines also attracts more positive tweets than the other airlines. This might explain the ranking differences between the algorithms – maybe the algorithms weight positive tweets differently to negative tweets.
Then the code creates a comparison word cloud, to show the different words in airline tweets that are associated with each emotion.

Step 6: Compare the Different Tweeting Behaviour of Different Twitter Users
Are some users more positive than others? Is this user behaviour different between the airlines? Do people who tweet more have a different sentiment to those who tweet about airlines less frequently? Are particular users dragging the average up or down? To answer these questions, I have tracked the 100 users who tweeted the most about these airlines.
# get the user summaries of the results
users = ddply(tweets, ~ Airline + UserName, summarize, num_tweets = length(positive), ave_sentiment = mean(bing),
ave_negative = mean(negative), ave_positive = mean(positive), ave_anger = mean(anger))
sizeSentiment = ddply(users, ~ num_tweets, summarize, ave_sentiment = mean(ave_sentiment),
ave_negative = mean(ave_negative), ave_positive = mean(ave_positive), ave_anger = mean(ave_anger))
sizeSentiment$num_tweets = as.numeric(sizeSentiment$num_tweets)
# plot users positive versus negative with bubble plot
cutoff = sort(users$num_tweets, decreasing = TRUE)[100]
ggplot(users[users$num_tweets > cutoff,], aes(x = ave_positive, y = ave_negative, size = num_tweets, fill = Airline)) +
geom_point(shape = 21) +
ggtitle("100 Most Prolific Tweeters About Airlines") +
labs(x = "Positive Sentiment", y = "Negative Sentiment")
#
ggplot(sizeSentiment, aes(x = num_tweets, y = ave_sentiment)) + geom_point() + stat_smooth(method = "loess", size = 1, span = 0.35) +
ggtitle("Number of Tweets versus Sentiment") + scale_x_log10() +
labs(x = "Positive Sentiment", y = "Negative Sentiment")
Firstly let’s look at the behaviour of individual users:
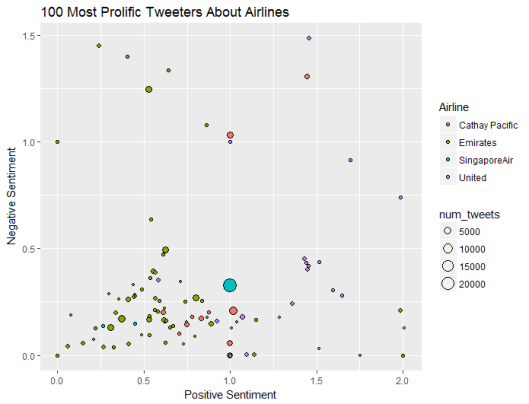
Top user sentiment is quite different by airline. Emirates has a number of frequent tweeters who are unemotional, who on average post neither positive nor negative sentiment. United Airlines attracts more emotional posts. Singapore Air and Cathay Pacific have big users that post a lot of tweets about them.
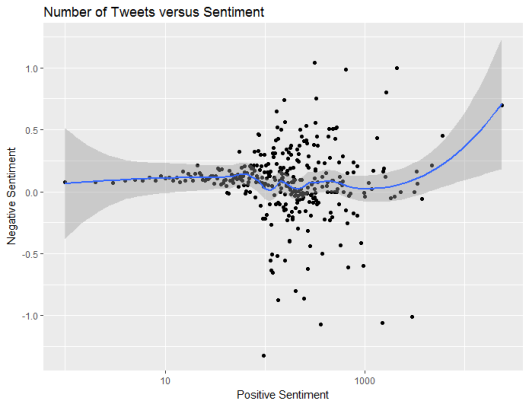
However, on average bigger frequent tweeters post a similar balance of positive and negative content to smaller users who tweet infrequently.
Step 7: Compare The Words Used to Describe Each Airline
In order to explain the differences in sentiment, we can create a word cloud that contrasts the words used in posts about each airline.
# Join texts in a vector for each company
txt1 = paste(tweets$Text[tweets$Airline == 'United'], collapse=" ")
txt2 = paste(tweets$Text[tweets$Airline == 'SingaporeAir'], collapse=" ")
txt3 = paste(tweets$Text[tweets$Airline == 'Emirates'], collapse=" ")
txt4 = paste(tweets$Text[tweets$Airline == 'Cathay Pacific'], collapse=" ")
#
# put everything in a single vector
all = c(clean.text(txt1), clean.text(txt2), clean.text(txt3), clean.text(txt4))
#
# remove stop-words
# adding extra domain specific stop words
all = removeWords(all, c(stopwords("english"), 'singapore', 'singaporeair',
'emirates', 'united', 'airlines', 'unitedairlines',
'cathay', 'pacific', 'cathaypacific', 'airline',
'airlinesunited', 'emiratesemirates', 'pacifics'))
#
# create corpus
corpus = Corpus(VectorSource(all))
#
# create term-document matrix
tdm = TermDocumentMatrix(corpus)
#
# convert as matrix
tdm = as.matrix(tdm)
#
# add column names
colnames(tdm) = c('United', 'Singapore Air', 'Emirates', 'Cathay Pacific')
#
# Plot comparison wordcloud
layout(matrix(c(1, 2), nrow=2), heights=c(1, 4))
par(mar=rep(0, 4))
plot.new()
text(x=0.5, y=0.5, 'Word Comparison by Airline')
comparison.cloud(tdm, random.order=FALSE,
colors = c("#00B2FF", "red", "#FF0099", "#6600CC"),
title.size=1.5, max.words=250)
#
# Plot commonality cloud
layout(matrix(c(1, 2), nrow=2), heights=c(1, 4))
par(mar=rep(0, 4))
plot.new()
text(x=0.5, y=0.5, 'Word Commonality by Airline')
commonality.cloud(tdm, random.order=FALSE,
colors = brewer.pal(8, "Dark2"),
title.size=1.5, max.words=250)
The code above is quite similar to that in the previous step, except that this time we are comparing airlines instead of emotions.


Emirates includes “aniston”, presumably in reference to the marketing campaign involving Jennifer Aniston, while United includes “CEO” due to a number of news stories about United CEO’s including a resignation and a heart transplant.