
Tags
Tutorial: Using R and Twitter to Analyse Consumer Sentiment
Content
This year I have been working with a Singapore Actuarial Society working party to introduce Singaporean actuaries to big data applications, and the new techniques and tools they need in order to keep up with this technology. The working group’s presentation at the 2015 General Insurance Seminar was well received, and people want more. So we are going to run some training tutorials, and want to extend our work.
One of those extensions is text mining. Inspired by a CAS paper by Roosevelt C. Mosly Jnr, I thought that I’d try to create a simple working example of twitter text mining, using R. I thought that I could just Google for an R script, make some minor changes, and run it. If only it were as simple as that…
I quickly ran into problems that none of the on-line blogs and documentation fully deal with:
-
- Twitter changed its search API to require authorisation. That authorisation process is a bit time-consuming and even the most useful blogs got some minor but important details wrong.
- CRAN has withdrawn its sentiment package, meaning that I couldn’t access the key R library that makes the example interesting.
After much experimentation, and with the help of some R experts, I finally created a working example. Here it goes, step by step:
STEP 1: Log on to https://apps.twitter.com/
Just use your normal Twitter account login. The screen should look like this:

STEP 2: Create a New Twitter Application
Click on the “Create New App” button, then you will be asked to fill in the following form:
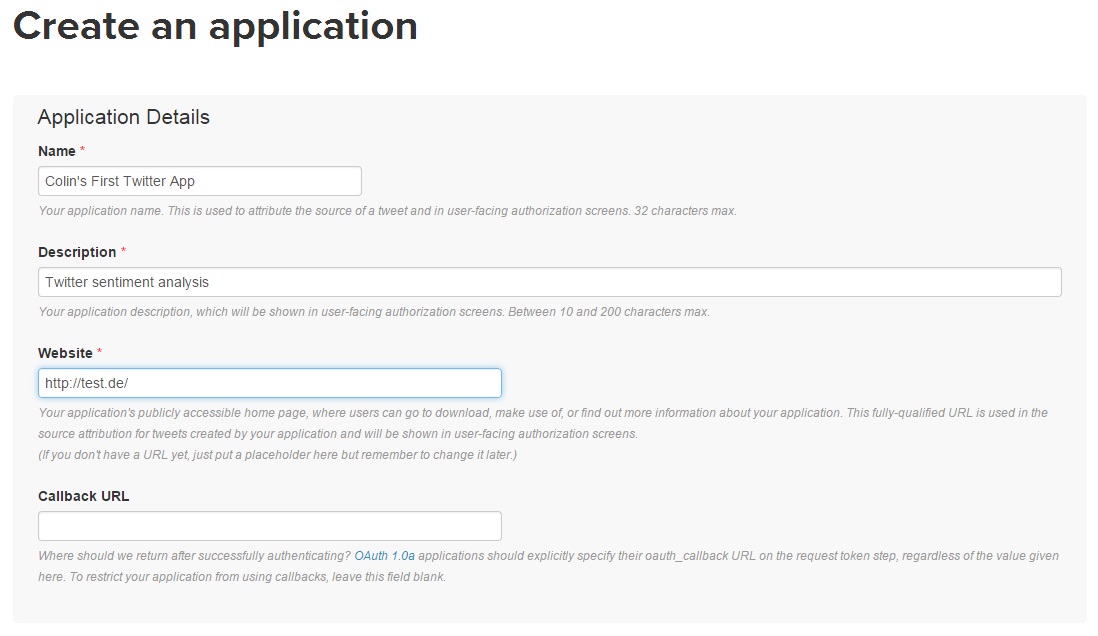
Choose your own application name, and your own application description. The website needs to be a valid URL. If you don’t have your own URL, then JULIANHI recommends that you use http://test.de/ , then scroll down the page.

Click “Yes, I Agree” for the Developer Agreement, and then click the “Create your Twitter application” button. You will see something like this:
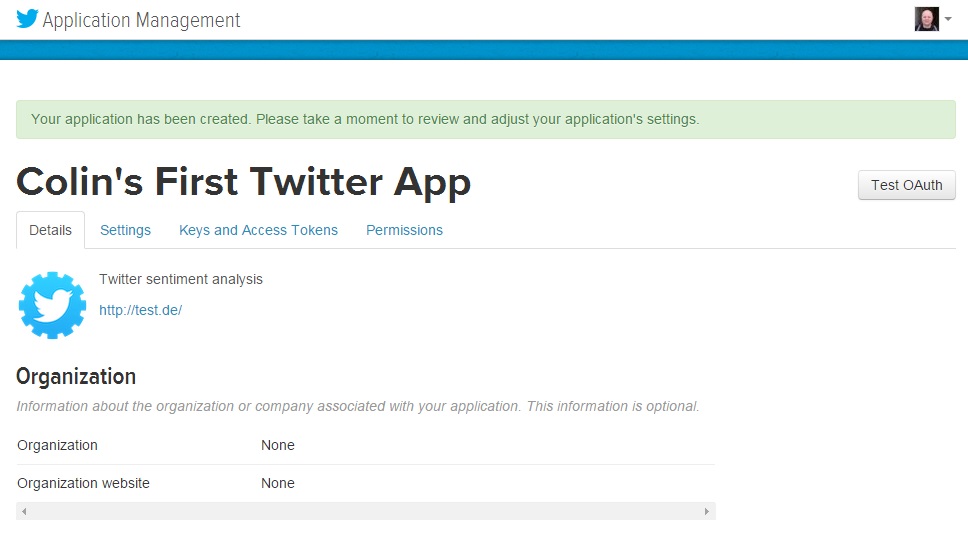
Go to the “Keys and Access Tokens” tab. Then look for the Consumer Key and the Consumer Secret. I have circled them in the image below. We will use these keys later in our R script, to authorise R to access the Twitter API.

Scroll down to the bottom of the page, where you will find the “Your Access Token” section.

Click on the button labelled “Create my access token”.
Look for the Access Token and Access Token Secret. We will use these in the next step, to authorise R to access the Twitter API.
STEP 3: Authorise R to Access Twitter
First we need to load the Twitter authorisation libraries. I like to use the pacman package to install and load my packages. The other packages we need are:
-
- twitteR : which gives an R interface to the Twitter API
- ROAuth : OAuth authentication to web servers
- RCurl : http requests and processing the results returned by a web server
The R script is below. But first remember to replace each “xxx” with the respective token or secret you obtained from the Twitter app page.
# authorisation
if (!require('pacman')) install.packages('pacman')
pacman::p_load(twitteR, ROAuth, RCurl)
api_key = 'xxx'
api_secret = 'xxx'
access_token = 'xxx'
access_token_secret = 'xxx'
# Set SSL certs globally
options(RCurlOptions = list(cainfo = system.file('CurlSSL', 'cacert.pem', package = 'RCurl')))
# set up the URLs
reqURL = 'https://api.twitter.com/oauth/request_token'
accessURL = 'https://api.twitter.com/oauth/access_token'
authURL = 'https://api.twitter.com/oauth/authorize'
twitCred = OAuthFactory$new(consumerKey = api_key, consumerSecret = api_secret, requestURL = reqURL, accessURL = accessURL, authURL = authURL)
twitCred$handshake(cainfo = system.file('CurlSSL', 'cacert.pem', package = 'RCurl'))
After substituting your own token and secrets for “xxx”, run the script. It will open a web page in your browser. Note that on some systems R can’t open the browser automatically, so you will have to copy the URL from R, open your browser, then paste the link into your browser. If R gives you any error messages, then check that you have pasted the token and secret strings correctly, and ensure that you have the latest versions of the twitteR, ROAuth and RCurl libraries by reinstalling them using the install.packages command.
The web page will look something like this:

Click the “Authorise app” button, and you will be given a PIN (note that your PIN will be different to the one in my example).

Copy this PIN to the clipboard and then return to R, which is asking you to enter the PIN.
![]()
Paste in, or type, the PIN from the Twitter web page, then click enter. R is now authorised to run Twitter searches. You only need to do this once, but you do need to use your token strings and secret strings again in your R search scripts.
Go back to https://apps.twitter.com/ and go to the “Setup” tab for your application.

For the Callback URL enter http://127.0.0.1:1410 . This will allow us the option of an alternative authorisation method later.
STEP 4: Install the Sentiment Package
Since the sentiment package is no longer available on CRAN, we have to download the archived source code and install it via this RScript:
if (!require('pacman')) install.packages('pacman&')
pacman::p_load(devtools, installr)
install.Rtools()
install_url('http://cran.r-project.org/src/contrib/Archive/Rstem/Rstem_0.4-1.tar.gz')
install_url('http://cran.r-project.org/src/contrib/Archive/sentiment/sentiment_0.2.tar.gz')
Note that we only have to download and install the sentiment package once.
UPDATE: There’s a new package on CRAN for sentiment analysis, and I have written a tutorial about it.
STEP 5: Create A Script to Search Twitter
Finally we can create a script to search twitter. The first step is to set up the authorisation credentials for your script. This requires the following packages:
- twitteR : which gives an R interface to the Twitter API
- sentiment : classifies the emotions of text
- plyr : for splitting text
- ggplot2 : for plots of the categorised results
- wordcloud : creates word clouds of the results
- RColorBrewer : colour schemes for the plots and wordcloud
- httpuv : required for the alternative web authorisation process
- RCurl : http requests and processing the results returned by a web server
if (!require('pacman')) install.packages('pacman')
pacman::p_load(twitteR, sentiment, plyr, ggplot2, wordcloud, RColorBrewer, httpuv, RCurl, base64enc)
options(RCurlOptions = list(cainfo = system.file('CurlSSL', 'cacert.pem', package = 'RCurl')))
api_key = 'xxx'
api_secret = 'xxx'
access_token = 'xxx'
access_token_secret = 'xxx'
setup_twitter_oauth(api_key,api_secret,access_token,access_token_secret)
Remember to replace the “xxx” strings with your token strings and secret strings.
Using the setup_twitter_oauth function with all four parameters avoids the case where R opens a web browser again. But I have found that it can be problematic to get this function to work on some computers. If you are having problems, then I suggest that you try the alternative call with just two parameters:
setup_twitter_oauth(api_key,api_secret)
This alternative way opens your browser and uses your login credentials from your current Twitter session.
Once authorisation is complete, we can run a search. For this example, I am doing a search on tweets mentioning a well-known brand: Starbucks. I am restricting the results to tweets written in English, and I am getting a sample of 10,000 tweets. It is also possible to give date range and geographic restrictions.
# harvest some tweets
some_tweets = searchTwitter('starbucks', n=10000, lang='en')
# get the text
some_txt = sapply(some_tweets, function(x) x$getText())
Please note that the Twitter search API does not return an exhaustive list of tweets that match your search criteria, as Twitter only makes available a sample of recent tweets. For a more comprehensive search, you will need to use the Twitter streaming API, creating a database of results and regularly updating them, or use an online service that can do this for you.
Now that we have tweet texts, we need to clean them up before doing any analysis. This involves removing content, such as punctuation, that has no emotional content, and removing any content that causes errors.
# remove retweet entities
some_txt = gsub('(RT|via)((?:\\b\\W*@\\w+)+)', '', some_txt)
# remove at people
some_txt = gsub('@\\w+', '', some_txt)
# remove punctuation
some_txt = gsub('[[:punct:]]', '', some_txt)
# remove numbers
some_txt = gsub('[[:digit:]]', '', some_txt)
# remove html links
some_txt = gsub('http\\w+', '', some_txt)
# remove unnecessary spaces
some_txt = gsub('[ \t]{2,}', '', some_txt)
some_txt = gsub('^\\s+|\\s+$', '', some_txt)
# define 'tolower error handling' function
try.error = function(x)
{
# create missing value
y = NA
# tryCatch error
try_error = tryCatch(tolower(x), error=function(e) e)
# if not an error
if (!inherits(try_error, 'error'))
y = tolower(x)
# result
return(y)
}
# lower case using try.error with sapply
some_txt = sapply(some_txt, try.error)
# remove NAs in some_txt
some_txt = some_txt[!is.na(some_txt)]
names(some_txt) = NULL
Now that we have clean text for analysis, we can do sentiment analysis. The classify_emotion function is from the sentiment package and “classifies the emotion (e.g. anger, disgust, fear, joy, sadness, surprise) of a set of texts using a naive Bayes classifier trained on Carlo Strapparava and Alessandro Valitutti’s emotions lexicon.”
# Perform Sentiment Analysis # classify emotion class_emo = classify_emotion(some_txt, algorithm='bayes', prior=1.0) # get emotion best fit emotion = class_emo[,7] # substitute NA's by 'unknown' emotion[is.na(emotion)] = 'unknown' # classify polarity class_pol = classify_polarity(some_txt, algorithm='bayes') # get polarity best fit polarity = class_pol[,4] # Create data frame with the results and obtain some general statistics # data frame with results sent_df = data.frame(text=some_txt, emotion=emotion, polarity=polarity, stringsAsFactors=FALSE) # sort data frame sent_df = within(sent_df, emotion <- factor(emotion, levels=names(sort(table(emotion), decreasing=TRUE))))
With the sentiment analysis done, we can start to look at the results. Let’s look at a histogram of the number of tweets with each emotion:
# Let’s do some plots of the obtained results
# plot distribution of emotions
ggplot(sent_df, aes(x=emotion)) +
geom_bar(aes(y=..count.., fill=emotion)) +
scale_fill_brewer(palette='Dark2') +
labs(x='emotion categories', y='number of tweets') +
ggtitle('Sentiment Analysis of Tweets about Starbucks\n(classification by emotion)') +
theme(plot.title = element_text(size=12, face='bold'))

Most of the tweets have unknown emotional content. But that sort of makes sense when there are tweets such as “With risky, diantri, and Rizky at Starbucks Coffee Big Mal”.
Let’s get a simpler plot, that just tells us whether the tweet is positive or negative.
# plot distribution of polarity
ggplot(sent_df, aes(x=polarity)) +
geom_bar(aes(y=..count.., fill=polarity)) +
scale_fill_brewer(palette='RdGy') +
labs(x='polarity categories', y='number of tweets') +
ggtitle('Sentiment Analysis of Tweets about Starbucks\n(classification by polarity)') +
theme(plot.title = element_text(size=12, face='bold'))

So it’s clear that most of the tweets are positive. That would explain why there are more than 21,000 Starbucks stores around the world!
Finally, let’s look at the words in the tweets, and create a word cloud that uses the emotions of the words to determine their locations within the cloud.
# Separate the text by emotions and visualize the words with a comparison cloud
# separating text by emotion
emos = levels(factor(sent_df$emotion))
nemo = length(emos)
emo.docs = rep('', nemo)
for (i in 1:nemo)
{
tmp = some_txt[emotion == emos[i]]
emo.docs[i] = paste(tmp, collapse=' ')
}
# remove stopwords
emo.docs = removeWords(emo.docs, stopwords('english'))
# create corpus
corpus = Corpus(VectorSource(emo.docs))
tdm = TermDocumentMatrix(corpus)
tdm = as.matrix(tdm)
colnames(tdm) = emos
# comparison word cloud
comparison.cloud(tdm, colors = brewer.pal(nemo, 'Dark2'),
scale = c(3,.5), random.order = FALSE, title.size = 1.5)

Word clouds give a more intuitive feel for what people are tweeting. This can help you validate the categorical results you saw earlier.
And that’s it for this post! I hope that you can get Twitter sentiment analysis working on your computer too.
UPDATE: There’s a new package on CRAN for sentiment analysis, and I have written a tutorial about it.

Hi Colin,
Thank you for the detailed post.
I get the following error while running the following code:
twitCred$handshake(cainfo = system.file(‘CurlSSL’, ‘cacert.pem’, package = ‘RCurl’))
Error in function (type, msg, asError = TRUE) :
Failed to connect to api.twitter.com port 443: Timed out
Please advice
Please see below my session info:
R version 3.3.1 (2016-06-21)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 7 x64 (build 7601) Service Pack 1
locale:
[1] LC_COLLATE=English_United Kingdom.1252 LC_CTYPE=English_United Kingdom.1252
[3] LC_MONETARY=English_United Kingdom.1252 LC_NUMERIC=C
[5] LC_TIME=English_United Kingdom.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] base64enc_0.1-3 pacman_0.4.1 RCurl_1.95-4.8 bitops_1.0-6 ROAuth_0.9.6
[6] twitteR_1.1.9 devtools_1.12.0
loaded via a namespace (and not attached):
[1] digest_0.6.9 withr_1.0.2 R6_2.1.2 DBI_0.4-1 git2r_0.15.0
[6] httr_1.2.1 curl_0.9.7 rjson_0.2.15 tools_3.3.1 bit64_0.9-5
[11] bit_1.1-12 memoise_1.0.0 openssl_0.9.4
LikeLike
Hi Abhijit,
That sounds like a problem with your firewall.
Colin
LikeLike
Then do we solve this, I have the same problem too.
LikeLike
Hi colin, thanks for your feedback, any idea on how to solve this. I encountered this problem too.
Mackay
LikeLike
Sorry I don’t know how to fix your firewall. Colin
LikeLike
sentiment package is not longer available
LikeLike
That’s why I show how to install from an archived version.
LikeLike
Hi,
I liked your tutorial, but could you tell me which version of R you use?
I’m using version R-3.3.2 and some packages quoted in step 4, like Rtools and Sentiment, do not exist for that version.
I know that I need to adapt and look for packages that are closer to the one indicated in the article, I’m looking for, if you have any indication, thank you already.
Up until.
LikeLike
Hi Juliana,
RTools does exist for your version of R.
Sentiment is no longer supported by CRAN, but you can still use an archived version. My blog explained how to do that.
Colin
LikeLike
Hi Colin,
I have some questions: the sentimentr package, can also be used to create the ranking of feelings? Is there a function inside it that is similar to classify_emo and classify_pol? I found inside the cran and untar the package sentiment, then I installed in the R and with the library (sentiment), the message I have is library (sentiment)
Error in library (sentiment):
‘Sentiment’ is not a valid installed package. Any idea?
LikeLike
Hi Juliana.
Sorry I’ve never used the sentimentr package, so I don’t know its capabilities.
You need to follow the instructions in my blog about how to install the sentiment package. If you got that error message then something has gone wrong. Without seeing the log I cannot comment what that could be.
Colin
LikeLike
Really cool stuff. I am trying to get all of these actual sentiment numbers for a list of 100 movies and actors then k nearest neighbors some soon to come movies to predict if they will be successful or not.
Can you help me extract a vector of the number of surprise/anger/etc tweets and number of pos neg tweets
LikeLike
Hi Matthew,
The way to get the tweets with a particular emotion is:
tmp = some_txt[emotion == particularEmotion]
Colin
LikeLike
Hi Colin,
yes I need help me, please. Follow add the log.
p.s.: What you are after # are my comments.
I haven’t access to server, so run everything in Windows 7.0.
———————————————————————————————————–
> library(“pacman”, lib.loc=”C:/Program Files/R/R-3.3.1/library”)
> install.Rtools()
No need to install Rtools – You’ve got the relevant version of Rtools installed
> install.URL(‘http://cran.r-project.org/src/contrib/Archive/Rstem/Rstem_0.4-1.tar.gz’)
trying URL ‘http://cran.r-project.org/src/contrib/Archive/Rstem/Rstem_0.4-1.tar.gz’
Content type ‘application/x-gzip’ length 275962 bytes (269 KB)
downloaded 269 KB
###Ok, install the Rtools. Great…….
The file was downloaded successfully into:
C:/Users/JULIAN~1.SOU/AppData/Local/Temp\RtmpUBQbNB/Rstem_0.4-1.tar.gz
Running the installer now…
Installation status: TRUE . Removing the file:
C:/Users/JULIAN~1.SOU/AppData/Local/Temp\RtmpUBQbNB/Rstem_0.4-1.tar.gz
(In the future, you may keep the file by setting keep_install_file=TRUE)
###Ok, Rstem
> install.URL(‘http://cran.r-project.org/src/contrib/Archive/sentiment/sentiment_0.2.tar.gz’)
trying URL ‘http://cran.r-project.org/src/contrib/Archive/sentiment/sentiment_0.2.tar.gz’
Content type ‘application/x-gzip’ length 38880 bytes (37 KB)
downloaded 37 KB
The file was downloaded successfully into:
C:/Users/JULIAN~1.SOU/AppData/Local/Temp\RtmpUBQbNB/sentiment_0.2.tar.gz
Running the installer now…
Installation status: TRUE . Removing the file:
C:/Users/JULIAN~1.SOU/AppData/Local/Temp\RtmpUBQbNB/sentiment_0.2.tar.gz
(In the future, you may keep the file by setting keep_install_file=TRUE)
###ok, finally SENTIMENT!!!!!!!!
> if(!require(‘pacman’)) install.packages(‘pacman’)
> pacman::p_load(twitteR, sentiment, plyr, ggplot2, wordcloud, RColorBrewer, httpuv, RCurl, base64enc)
also installing the dependency ‘slam’
trying URL ‘https://cran.rstudio.com/bin/windows/contrib/3.3/slam_0.1-39.zip’
Content type ‘application/zip’ length 115456 bytes (112 KB)
downloaded 112 KB
trying URL ‘https://cran.rstudio.com/bin/windows/contrib/3.3/wordcloud_2.5.zip’
Content type ‘application/zip’ length 533605 bytes (521 KB)
downloaded 521 KB
package ‘slam’ successfully unpacked and MD5 sums checked
package ‘wordcloud’ successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\juliana.souza\AppData\Local\Temp\RtmpUBQbNB\downloaded_packages
wordcloud installed
trying URL ‘https://cran.rstudio.com/bin/windows/contrib/3.3/httpuv_1.3.3.zip’
Content type ‘application/zip’ length 898765 bytes (877 KB)
downloaded 877 KB
package ‘httpuv’ successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\juliana.souza\AppData\Local\Temp\RtmpUBQbNB\downloaded_packages
base64enc installed
Warning messages:
1: In p_install(package, character.only = TRUE, …) : sentiment
2: In library(package, lib.loc = lib.loc, character.only = TRUE, logical.return = TRUE, :
there is no package called ‘sentiment’
3: package ‘wordcloud’ was built under R version 3.3.2
4: package ‘RColorBrewer’ was built under R version 3.3.2
5: package ‘httpuv’ was built under R version 3.3.2
6: package ‘base64enc’ was built under R version 3.3.2
7: In pacman::p_load(twitteR, sentiment, plyr, ggplot2, wordcloud, :
Failed to install/load:
sentiment
#and???? the sentiment is library, but I not understando what happened
I know I’m a beginner.
Thanks you for patience.
LikeLike
Does it work if you change your code to:
library(“pacman”)
install.Rtools()
install.URL(‘http://cran.r-project.org/src/contrib/Archive/Rstem/Rstem_0.4-1.tar.gz’)
library(“Rstem”)
install.URL(‘http://cran.r-project.org/src/contrib/Archive/sentiment/sentiment_0.2.tar.gz’)
library(“sentiment”)
pacman::p_load(twitteR, plyr, ggplot2, wordcloud, RColorBrewer, httpuv, RCurl, base64enc)
LikeLiked by 1 person
Thanks Colin, now I get.
LikeLiked by 1 person
Hello Colin,
Thank you very much for such a detailed explanation. I was actually working to do Twitter analysis , but evrytime ran into issues (because of lack of knowledge).
Thanks Once again for Enlightening.
Faiz.,
LikeLiked by 1 person
Happy new year Colin …in the first go itself i was able to run the script without any issue and successful give the output .
I would really like to appreciate your detail of analysis which is very much helpful and came to this page after so much of research in the search engine for this topic .
I hope you will come up with more post like in this year which will help many people .
LikeLike
Hi Colin,
Thank you so much for providing this information. One of the things I was curious about was to know if there was a way to at the Lat and Long to each tweet. I’d really be curious to see any regional difference in Sentiment for the tweets.
Thanks!
LikeLike
Hi Pat,
The location data in Twitter feeds can be unreliable, often missing.
Colin
LikeLike
Hi Colin,
First of all thank you for sharing the information. I would like to know if there is an alternative package available for classify_emotions since it is not avaliable in the version 3.3.3 of R.
LikeLiked by 1 person
Hi Darshana,
The blog explains how to manually install sentiment from the archive- ensure that you follow the steps I describe. If you’re interested in other libraries, then check out the discussion at https://sites.google.com/site/miningtwitter/questions/sentiment/sentiment
Colin
LikeLike
Hey collin , thank you for this interesting tutoriel . plz how can i solve this :
> class_emo = classify_emotion(some_txt, algorithm=’bayes’, prior=1.0)
Error: could not find function “classify_emotion”
LikeLike
Hi Khadija,
That error is because you didn’t install the “sentiment” package. This package needs special attention to install, so please follow the instructions in the blog.
Colin
LikeLike
Pingback: Tutorial: Sentiment Analysis of Airlines Using the syuzhet Package and Twitter | Keeping Up With The Latest Techniques
Hi colin, Please help.
I have followed the code mentioned initially and I have this error
if (!require(‘pacman’)) install.packages(‘pacman’)
> pacman::p_load(twitteR, ROAuth, RCurl)
>
> api_key = ‘******0ZXvXS4Idif9Vx5xTB’
> api_secret = ‘A0iK*****ODR****4Jv*****GInW’
> access_token = ‘160*******BLFK6ZHTkl93CblFTUGUpEQC7DU53jDsSMuZp3Bp’
> access_token_secret = ‘tV4y3ikl***************c4s**Tq’
>
> options(RCurlOptions = list(cainfo = system.file(‘CurlSSL’, ‘cacert.pem’, package = ‘RCurl’)))
>
> reqURL = ‘https://api.twitter.com/oauth/request_token’
> accessURL = ‘https://api.twitter.com/oauth/access_token’
> authURL = ‘https://api.twitter.com/oauth/authorize’
>
> twitCred = OAuthFactory$new(consumerKey = api_key, consumerSecret = api_secret, requestURL = reqURL, accessURL = accessURL, authURL = authURL)
>
> twitCred$handshake(cainfo = system.file(‘CurlSSL’, ‘cacert.pem’, package = ‘RCurl’))
Error in function (type, msg, asError = TRUE) :
Could not resolve host: api.twitter.com
>
LikeLike
Hi,
The message “Could not resolve host: api.twitter.com” means that there’s something wrong with your internet connection. It may be that your firewall is blocking R
Colin
LikeLiked by 1 person
Very good job, thx!!!
LikeLike
thank you very much for the informative explanation.
could u please tell me how to work on already extracted twitter data and saved as CSV file instead of searchTwitter(‘Keyword’, n=100, lang=’en’)?
thanks
LikeLike
Hi Hiba,
I have another blog where I do that: https://colinpriest.com/2017/04/30/tutorial-sentiment-analysis-of-airlines-using-the-syuzhet-package-and-twitter/
Colin
LikeLike
Hi, I found your code to be very useful. Kindly help me in finding the accuracy measures. The above code helps in finding the sentiments but how accurately it does?
Kindly calculate some accuracy measures and update
LikeLike
What type of accuracy measures are you expecting to see? What is the source of truth here?
LikeLike
The usual classification accuracy measures such as cross validation, precision & recall
LikeLike
They don’t apply to multiclass in the simple way that they apply to binary classification.
What’s the source of truth? What is the “correct” classification of a tweet?
LikeLike
Hello Sir, I have done classification using Bayes and SVM.
The output I got for both is different. While plotting, for bayes it shows “unknown” is greater and for SVM it shows “anger” is greater. The polarity also varies for both. So I want to know is there any measure to compare these both.
LikeLike
The only way to compare the models is to have the “correct” classification result to compare them by. In this tutorial we are using pre-built sentiment models, trained on different data. There’s no guarantee that these models are suitable for tweets about Starbucks. If you want to know the accuracy then you need to go through your tweet data and manually label the sentiment for each one.
LikeLike
Thank you Sir….
LikeLike
Hi Colin
I tried above code and I am getting error as shown below
setup_twitter_oauth(api_key,api_secret)
[1] “Using browser based authentication”
Error in init_oauth1.0(self$endpoint, self$app, permission = self$params$permission, :
Unauthorized (HTTP 401).
LikeLike
Based upon that error message it looks like you didn’t set up your Twitter account or authorisation correctly.
LikeLike
Hi Colin,
Before entering my authorization pin it is just throwing an Error: Authorization Required… please help me out
LikeLike
Hi Yaswanth. The Twitter API can be quite pedantic and buggy. Double check your code, and maybe try on a different computer.
LikeLike
Can you tell me how to give Callback url for my application
LikeLike
Sorry I’ve never used callbacks. Maybe search Stack Overflow for an example?
LikeLike
thank you sir.. it help me a lot. Keep sharing such blog.
LikeLiked by 1 person